As I delve further and further into “all things security” along my career path, it has become clear to me that one of the key skills a good Security Professional must have is the ability to filter out noise, and focus on identifying the critical pieces of information that require action, while safely being able to ignore the rest. Modern security tools, whether they are Firewalls, IDS/IPS, Proxies, Web Application Firewalls, Content Filters, etc. all collect, report, and alert on a lot of information. It can be overwhelming, and this is especially true for smaller, flatter IT teams that perhaps don’t have a dedicated Security Operations Center (SOC), or even an actual Security Team. Quite often, the “Security Team” is one person, and that person may also fill the role of Network Administrator, Server Administrator, or any number of other roles that some larger IT teams might have distributed across several individuals.
In these situations, having a tool or process that can consolidate and help with filtering and focusing the important data is key to being able to avoid information paralysis – the idea of having too much information to really be able to act on any of it in a meaningful way. This is SIEM – or Security Information and Event Management. Now, I’ve found SIEM can be interchangably used as a noun when referring to a specific tool that performs this fuction, or as a verb when describing the act of processing the data from multiple sources into actionable information. In either case, the end result is the most critical – the ability to gather data from multiple sources, and render it down to something useful, and actionable.
This week at Security Field Day 3, I was fortunate to participate in a fantastic conversation with PathSolutions CTO Tim Titus, as he presented TotalView Security Operations Manager and its capabilities as a SecOps tool that can greatly improve awareness and response time to security events within your network.
60 Second Decisions
Investigating alerts can be tedious, and can take up a lot of time, only to find out in many cases that the alert was benign, and doesn’t require intervention. TotalView Security Operations Manager is a security orchastration, automation, and response (SOAR) product designed to optimize event response, reduce wasted time on false positives, and provide a faster path to quarantine and remediation.
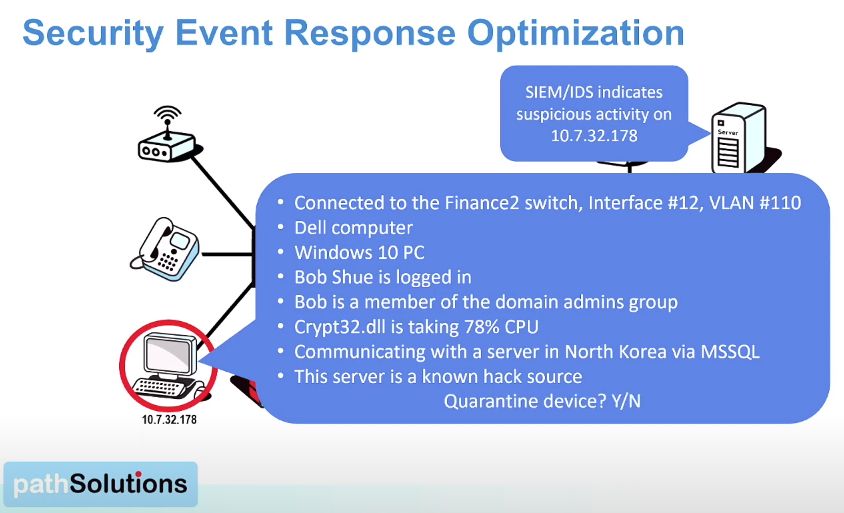
Immediately upon an indication of suspicious activity, the Security Operations Manager dashboard provides almost instant details for the potentially compromised asset: the switch and port it is connected to, what it is (operating system, manufacturer), who is logged into it, what security groups/access they have, what Indicators of Compromise (IoC) are detected, and what destination(s) this asset is talking to on or outside the network, and whether any of these locations could be a known malicious or C&C (Command and Control) destination. With information presented, the option to quickly quarantine the asset is presented, and is as simple as shutting down the switch port with the click of a button. All of this information is sourced natively, with no installed agents, no need for SPAN ports, or network taps. It is all done thorugh NetFlow, SNMP, and WMI (Windows Management Instrumentation).
In roughly 60 seconds, enough information is presented to enable you to make a swift, informed decision on what action to take, and saves countless minutes our hours of correlating information from disparate tools or infrastructure in order to determine if there is in fact a problem. Should this end user workstation suddenly start talking to a known bad IP in North Korea? Probably not! Shut it down.
Totalview Security Operations Manager doesn’t stop there, and Tim walked us through an in-depth demo of their solution.
Device Vulnerability Reporting
It would be almost too easy to insert a Buzz Lightyear meme captioned with “Vulnerabilities. Vulnerabilities everywhere…” because it’s true. Just a few days ago (as of this writing), Microsoft’s Patch Tuesday saw the release of 111 fixes for various vulnerabilites, the third largest in Microsoft’s history. Keeping up with patches and software updates for any size network can be a daunting task, and more often than not, there is simply not enough time to patch absolutely everything. We must pick and choose what gets patched by evaluating risk, and triaging updates based on highest risk or exposure.
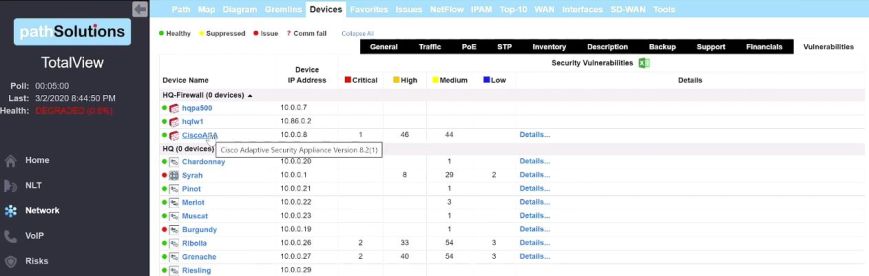
TotalView Security Operations Manager is able to provide constant monitoring of all of your network assets for operating system or device vulnerabilities by referencing the NIST Vulnerability Database (NVD) every 24 hours, identifying those with a known vulnerability, and allowing you to dig deeper into the CVE to assist with risk assesment.
Communications Monitoring and Geographic Risk Profiling
Do you know which of your devices are talking to each other? Do you know where in the world your devices are sending data? These are both questions that can sometimes be difficult to answer without some baseline understanding of all of the traffic across your network. With Communications Policy Monitoring and Alerting, Security Operations Manager is able to trigger an alert when a device starts communicating with another device that it shouldn’t be talking to, based on policies you define.
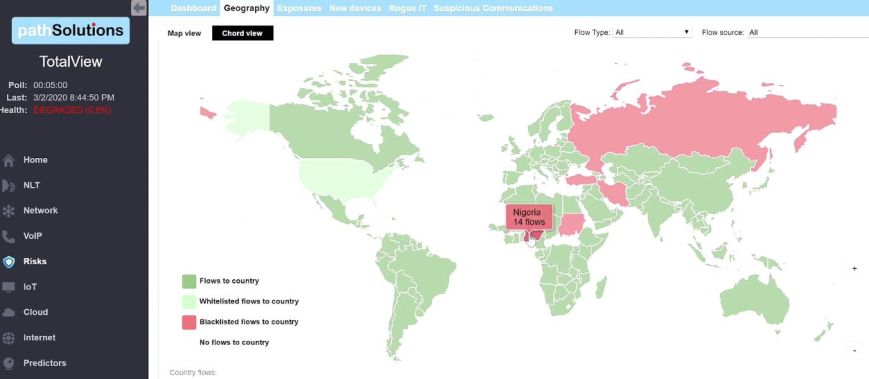
The Geographic Risk profiling looks at where your devices are communicating globally, presented in an easy to understand map view, quickly showing if and when you may have an asset that is sending data somewhere it shouldn’t. The Chord View within the dashboard breaks out the number of flows by country, which presents a nice quick visual, giving you an idea of the percentage of your data is flowing to appropriate vs. questionable destinations.
New Device Discovery and Interrogation
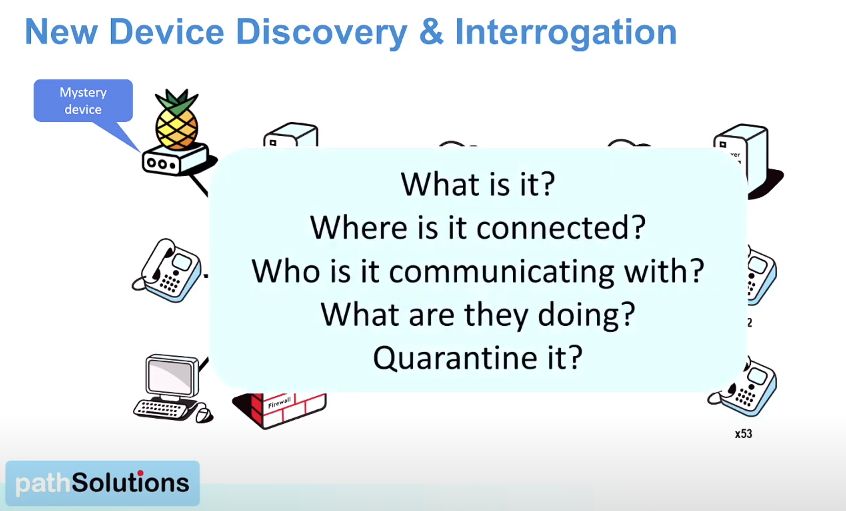
Not everyone has a full Network Access Control (NAC) system in place. Let’s be honest, they’re not simple to set up, and can often be responsible for locking out legitimate devices from accessing the network at inconvenient times. Without NAC, network operators are often blind to new devices being connected. With Security Operations Manager, in the even that new devices are connected, they are discovered, and interrogated to find out what they are, and what they are communicating with. This gives tremendous flexibility to monitor random items being connected, and making it simple to decide on how they should be treated.
Rapid Deployment
Touting a 30 minute deployment, with only a single 80MB Windows VM required, this seems to good to be true, right? Maybe. There are some dependancies here that, if not already in place, will require some ground work to get all of the right information flowing to the tool. As Tim mentions, there are no requirements for agents to be installed, or taps, but that all of the data is sourced natively via SNMP, NetFlow and WMI. This means, all you need to provide the Security Operations Manager VM is SNMP access to all of your routers, switches, firewalls, gateways, etc. as well as access to the NetFlow data, and WMI credentials for your Windows environment. Setting all of that up, if it’s not already in place, will take some planning, and time. It’s especially important to ensure that SNMP is set up correctly, and securely. Here, the ability of Security Operations Manager to be able to gather 100% of the data from your network relies on the fact that you correctly configured and prepared 100% of your devices for these protocols.
Final Thoughts
Every so often I will come away from a product presentation and really feel like it’s a product that was meant for me, or other folks who find themselves on smaller teams but still managing decent-sized infrastructure. IT teams tend to run slim, and the prevalence of automation, and the need for it have justified some of the lower staffing ratios seen throughout the industry. Less so in large enterprise, but in mid-size or smaller enterprise networks, tools like Security Operations Manager help reduce the noise, and expedite decision making when it comes to monitoring and identifying problematic or compromised devices within the network.
PathSolutions have evolved what began as a tool for network administrators, and added insights for voice/telecom administrators, into a product that now takes all of the data they were already collecting from all of your infrastructure, and boils it down to something quickly parsed and understood by security administrators. Even better if you happen to fill all three of those roles on your infrastructure team.
It’s surpisingly simple, lightweight, and very quick to get up and running. I’m looking forward to diving deeper into Security Operations Manager’s sandbox myself, and invite you to as well.
Check out the full presentation and demo from Security Field Day 3.
Also, feel free to take a look at the PathSolutions Sandbox to try it yourself.
Nerdy Bullets
– All written in C/C++
– Backend storage is SQL Lite
– 13 months data retention (default) – but can be scaled, or descaled based on specific needs
– Data cleanup is done via SQL scripts, and can be customized based on your retention needs
– API integration with some firewall vendors (Palo Alto, as an example) to poll detailed data where SNMP is lacking
– Integrated NMAP to scan devices on the fly
– IP geolocation db updated every 24 hours
– Flow support – NetFlow, sFlow, and (soon) JFlow
– Security intelligence feeds from Firehall

